검색이 느린 이유가 fetch join 때문이었다

요약
게시글 검색 API를 구현하면서 N+1 문제를 해결하기 위해 fetch join 을 적용했다.
쿼리가 깔끔해지고, 기능도 정상 동작했다.
하지만 성능 테스트를 진행하던 중, 페이징이 DB가 아닌 메모리에서 처리되고 있는걸 발견했다.
이 글은 그 문제를 어떻게 인지했고, 왜 @BatchSize 를 선택했는지에 대한 기록이다.
문제 상황: N+1 문제 해결을 위한 fetch join 적용
게시글 목록 조회 시, 각 게시글 마다 태그를 조회하면서 전형적인 N+1 문제가 발생했다.
1
2
3
4
5
6
// 문제 상황
SELECT * FROM post; // 1번 쿼리
SELECT * FROM post_tag WHERE post_id = 1; // 게시글 1
SELECT * FROM post_tag WHERE post_id = 2; // 게시글 2
SELECT * FROM post_tag WHERE post_id = 3; // 게시글 3
// ... N번 반복
이를 해결하기 위해 fetch join을 적용했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@Override
public List<Post> searchPostByCondition(PostSearchCondition condition, Pageable pageable) {
return queryFactory
.select(post)
.from(post)
.join(post.tags, postTag).fetchJoin() // ← fetch join 적용
.where(
keywordLike(condition.keyword()),
tagEq(condition.tagNames()),
postStatusEq(condition.postStatuses()),
createdAtFrom(condition.createdFrom()),
createdAtTo(condition.createdTo())
).fetch();
}
N+1 문제는 해결됐고, 기능 테스트도 문제 없었다.
하지만 성능 테스트 단계에서 이상 징후가 나타났다.
성능 테스트 중 발견한 이상 징후
1. Pageable을 받지만 실제로는 사용되지 않음
- 메서드 시그니처에는
Pageable이 존재 - 하지만
.offset(),.limit()호출이 없음 - 결과적으로 모든 데이터를 한번에 조회
2. Hibernate 경고 로그 발생
1
HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory

3. 실제 실행 SQL에 LIMIT 절이 없음
나는 코드를 다음과 같이 작성했다.
1
2
.offset(0)
.limit(10)
하지만 DB 로그를 확인해보면 LIMIT 절이 없다.
1
2
3
4
SELECT ...
FROM post p
INNER JOIN post_tag pt ON p.id = pt.post_id
-- LIMIT 없음

왜 이런 문제가 발생할까?
1:N JOIN + 페이징의 본질적인 문제
다음과 같은 데이터 구조가 있다고 가정해보자.
1
2
3
Post 1 → Tag A, Tag B, Tag C
Post 2 → Tag D, Tag E
Post 3 → Tag F
JOIN 결과는 다음과 같다.
1
2
3
4
5
6
7
Row 기준 결과
1 | Post 1 | Tag A
2 | Post 1 | Tag B
3 | Post 1 | Tag C
4 | Post 2 | Tag D
5 | Post 2 | Tag E
6 | Post 3 | Tag F
여기서 LIMIT 2를 적용하면?
- DB는 Row 2개만 반환
- Post 1의 Tag C 누락
- 객체 단위 정합성 깨짐
👀 Hibernate의 선택: 메모리 페이징
Hibernate는 데이터 정합성을 지키기 위해 다음과 같이 동작한다.
- LIMIT 제거 후 전체 Row 조회
- 메모리에서 Post 엔티티로 조립
- 메모리에서 페이징 적용
발생할 수 있는 문제
게시글 10만개, 평균 태그 3개인 경우:
- DB → 300,000 Row 전송
- 메모리 → 100,000 Post 객체 생성
- 실제 사용 → 10개
- OOM 위험 + GC 증가 + 응답 시간 증가
📈 JMeter + VisualVM으로 메모리 사용량 분석
테스트 환경
- 데이터 규모: Post (100,000건), PostTag (300,000건)
- 부하 설정(JMeter): 5Users / Ramp-up 1s/ Loop 1
- 관찰 도구: VisualVM (Heap, CPU, GC), JMeter (Response Time)
지표 분석 결과
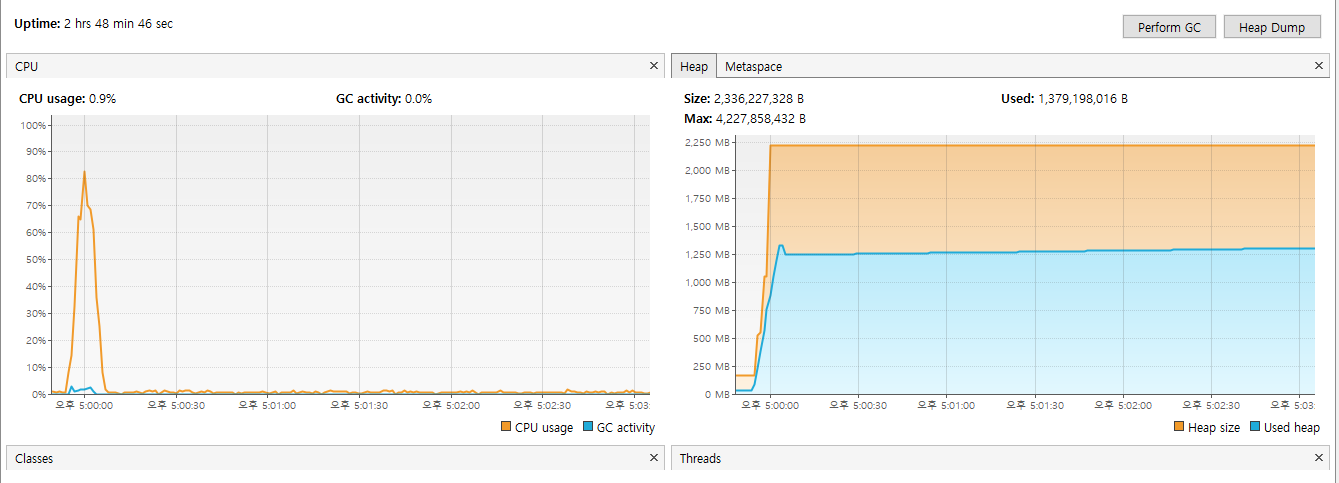
VisualVM 지표
- API 호출 직후, 평상시 250MB 미만이던 Used Heap 이 단 5개의 요청만으로 최대 1.38GB까지 상승
- DB에서 조회된 수십만 건의 데이터가 한꺼번에 JVM 메모리에 적재되는 과정에서 Heap 사용량이 약 600% 증가
- CPU 점유율 80%까지 상승
- 데이터를 자바 객체로 변환하기 위해 CPU 점유율이 80%까지 증가
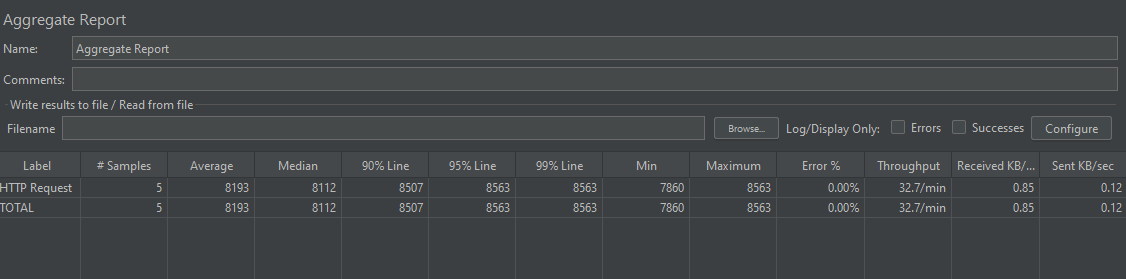
JMeter 지표
- 평균 응답 시간 8,193ms(약 8.2초) 기록
- 10건의 데이터를 보여주기 위해 전체 데이터를 메모리에 올리고 가공하는 비효율적인 연산으로 인해 응답 시간 증가
해결책: fetch join 대신 @BatchSize 사용
인메모리 페이징 문제를 해결하기 위해 DB 레벨의 페이징 쿼리를 활성화하고, 이 과정에서 발생하는 N+1 문제는 default_batch_fetch_size 설정을 통해 쿼리 횟수를 최소화하여 최적화했다.
코드 수정: fetchJoin() 제거
기존 코드에서 문제가 되었던 컬렉션 fetchJoin() 을 제거하고, DB 레벨에서 직접 데이터를 자르도록 수정했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
@Override
public List<Post> searchPostByCondition(PostSearchCondition condition, Pageable pageable) {
return queryFactory
.select(post)
.from(post)
.join(post.tags, postTag)
.where(
keywordLike(condition.keyword()),
tagEq(condition.tagNames()),
postStatusEq(condition.postStatuses()),
createdAtFrom(condition.createdFrom()),
createdAtTo(condition.createdTo())
)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
}
글로벌 설정 적용
application.yml에 전역 설정을 추가하여, 지연 로딩 시 100개씩 IN 절로 묶어서 조회하도록 최적화하였다.
1
2
3
4
5
6
7
8
jpa:
hibernate:
ddl-auto: update
show-sql: false
properties:
hibernate:
format_sql: true
default_batch_fetch_size: 100 # 대량 조회 성능 최적화
개선 후 지표 비교
개선 후 동일한 데이터 규모와 부하 조건에서 다시 테스트를 진행한 결과, 모든 지표에서 성능 향상을 확인했다.
지표 분석 결과
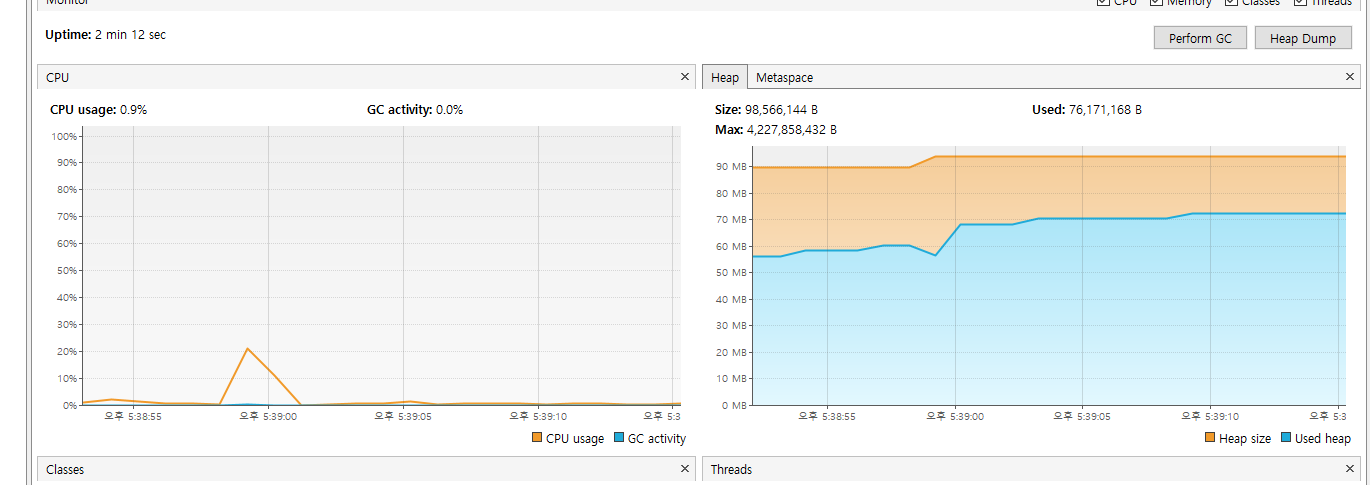
VisualVM 지표
- Used Heap 사용량: 1.38GB → 76MB (약 94% 감소)
- 300,000건의 데이터를 메모리에 올리지 않고 페이징 사이즈인 10개만 로드하게 되면서 영속성 컨텍스트의 무게가 급격히 가벼워졌다.
- CPU 점유율: 80% → 20% (75% 절감)
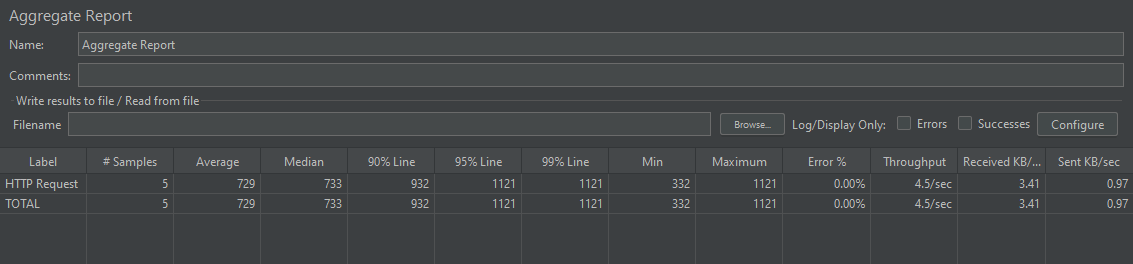
JMeter 지표
- 평균 응답 시간: 8,193ms → 729ms (약 11.2배 향상)
- DB 레벨에서 LIMIT절이 미적용됨에 따라, 필요한 10건을 넘어 테이블 전체를 훑는 Full Scan과 객체 생성 과정이 생략되면서 응답 속도가 획기적으로 단축되었다.
- 처리량: 32.7/min → 4.5/sec (약 8.2배 향상)
개선 결과
성능 측정 (게시글 100,000개 기준, 게시글 태그 300,000개 기준)
| 항목 | 개선 전 (Fetch Join) | 개선 후 (@BatchSize) | 개선율 / 효과 |
|---|---|---|---|
| 평균 응답 시간 | 8,193ms (8.2초) | 729ms (0.7초) | 91% ↓ (약 11.2배 향상) |
| 최대 메모리 점유 | 1,380MB (1.38GB) | 76MB | 94% ↓ (자원 가용성 확보) |
| CPU 피크 점유율 | 약 80% | 약 20% | 75% ↓ (연산 비용 절감) |
| 처리량 (Throughput) | 32.7 / min | 4.5 / sec | 약 8.2배 증가 |
| DB 쿼리 수 | 1번 (N+1은 해결되나 전체 조회) | 1 + 1번 (100개 단위 묶음) | 페이징 정합성 및 속도 확보 |
| 페이징 처리 방식 | Application (인메모리) | Database (LIMIT/OFFSET) | OOM 위험 원천 차단 |