HTTP의 기능:압축
HTTP에서의 압축: 웹 성능을 높이는 핵심 기술
웹 성능을 최적화하는 중요한 방법 중 하나는 압축을 활용하는 것이다. 압축을 통해 웹사이트에서 전송하는 데이터의 크기를 줄이면, 대역폭 사용량이 감소하고 페이지 로딩 속도가 향상된다. 일부 경우에는 70% 이상의 사이즈 감소 효과를 얻을 수도 있다. 다행히, 웹 개발자가 직접 압축을 구현할 필요는 없다. 대부분의 최신 브라우저와 서버가 이미 압축을 지원하고 있기 때문에, 개발자는 서버가 올바르게 구성되었는지만 확인하면 된다. HTTP에서 압축은 크게 세 가지 계층에서 이루어진다.
- 파일 포맷 자체의 압축: 일부 파일 형식은 저장 공간을 최적화하기 위해 자체적인 압축 방식을 사용한다.
- HTTP 계층에서의 압축: 웹 리소스가 서버에서 클라이언트로 전달될 때 압축된다.
- 네트워크 연결 계층에서의 압축: 서버와 클라이언트 간의 연결 수준에서 압축이 적용될 수 있다.
1. 파일 포맷 압축
각 데이터 유형은 중복된 정보를 포함하고 있어 압축을 통해 크기를 줄일 수 있다. 특히 텍스트 데이터는 60% 이상의 중복이 있을 수 있으며, 이미지, 오디오, 비디오와 같은 미디어 파일은 더욱 높은 중복을 가질 수도 있다. 이에 따라 다양한 압축 알고리즘이 개발되었다.
- 무손실 압축: 원본 데이터를 손상시키지 않고 크기를 줄이는 방식입니다.
- PNG, GIF 등의 이미지 포맷이 대표적이다.
- 손실 압축: 사람이 인지하기 어려운 정보를 제거하여 더 높은 압축률을 제공하는 방식
- JPEG 이미지, MP3 오디오, MP4 비디오 등이 있다.
- 혼합 압축(WebP 등): 손실 및 무손실 압축을 선택적으로 사용할 수 있는 포맷 이미 최적화된 파일을 추가로 압축하는 것은 큰 효과가 없으며, 오히려 오버헤드로 인해 파일 크기가 더 커질 수도 있다. 따라서 압축된 파일에는 추가적인 압축을 적용하지 않는 것이 좋다.
2. HTTP 계층에서의 압축 (종단 간 압축) ⭐⭐⭐
웹 사이트 성능 최적화에서 가장 큰 효과를 볼 수 있는 부분이 바로 종단 간(end-to-end) 압축이다. 이는 서버에서 압축된 데이터를 전송하고, 클라이언트(브라우저)에서 이를 해제하는 방식이다.
주요 압축 알고리즘
현재 웹에서 가장 많이 사용되는 두 가지 압축 알고리즘은 다음과 같다:
- Gzip: 가장 일반적으로 사용되는 텍스트 압축 방식으로, HTML, CSS, JavaScript 등의 파일을 압축하는 데 적합하다.
- Brotli (br): Gzip보다 높은 압축률을 제공하며, 최신 브라우저에서 지원된다.
압축 과정
- 클라이언트(브라우저)가
Accept-Encoding헤더를 통해 지원 가능한 압축 방식을 서버에 전달한다. - 서버는 지원되는 알고리즘을 확인한 후, 적절한 방식으로 응답을 압축하여
Content-Encoding헤더와 함께 클라이언트로 전송한다. - 클라이언트는 응답을 받아 압축을 해제하고 렌더링한다. 대부분의 텍스트 기반 파일(HTML, CSS, JS)은 압축을 활성화하는 것이 성능 향상에 도움이 되지만, 이미지, 오디오, 비디오는 이미 압축된 상태이므로 추가적인 압축을 적용할 필요가 없다.
실습
- 스프링 부트 프로젝트 생성
- 간단한 컨트롤러 작성
1
2
3
4
5
6
7
8
9
10
11
12
@RestController
public class ExController {
@GetMapping("/hello")
public ResponseEntity<String> hello() {
String message = "이건 gZip 압축입니다.";
return ResponseEntity.ok()
.contentType(MediaType.APPLICATION_JSON) // text/html로 변경
.body(message);
}
}
- application.properties 파일 설정
1 2 3
server.compression.enabled=true server.compression.mime-types=application/json server.compression.min-response-size=1
- 스프링 부트 애플리케이션 실행
- Postman으로 요청 전송
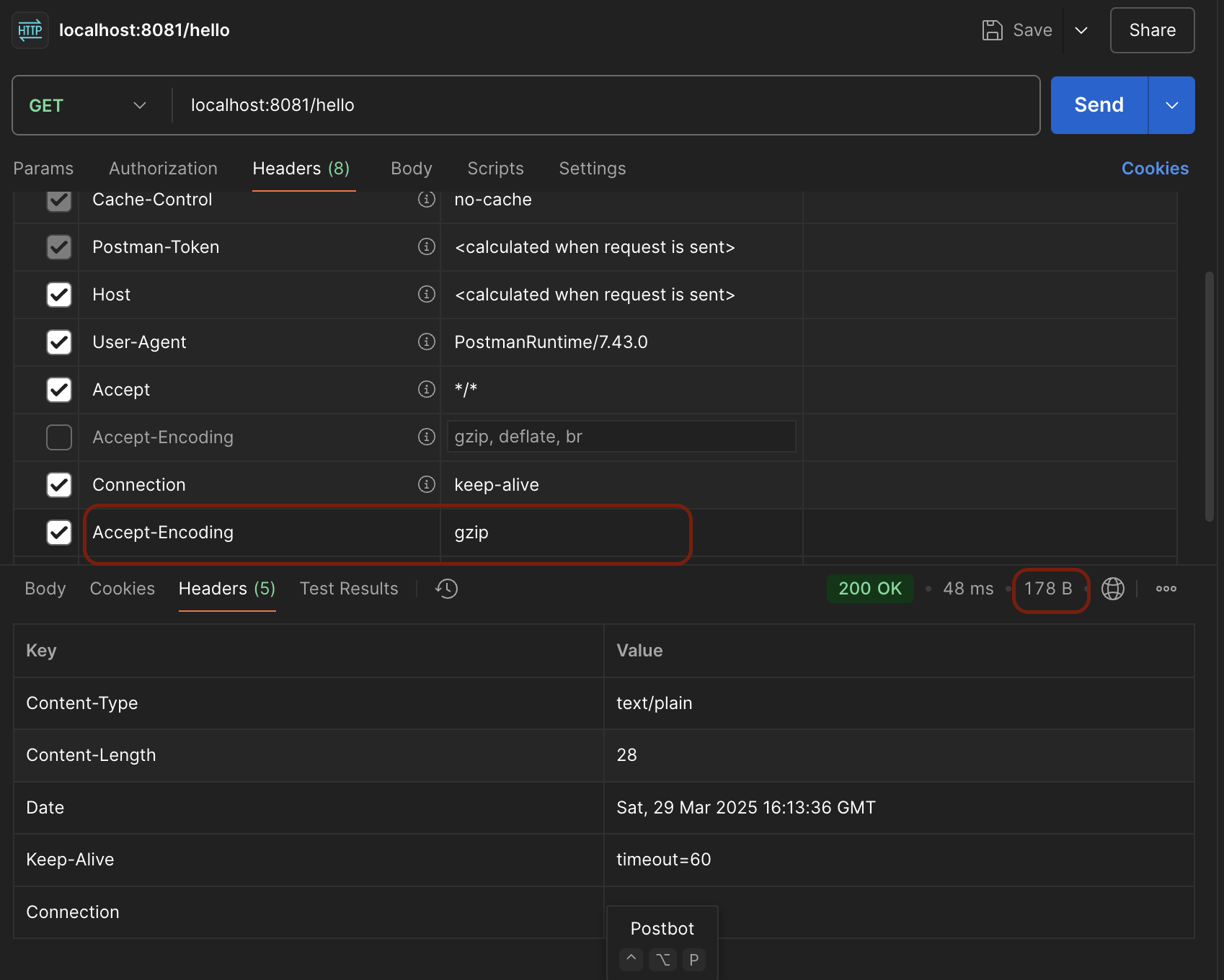
- 압축 하기 전
- 압축 후
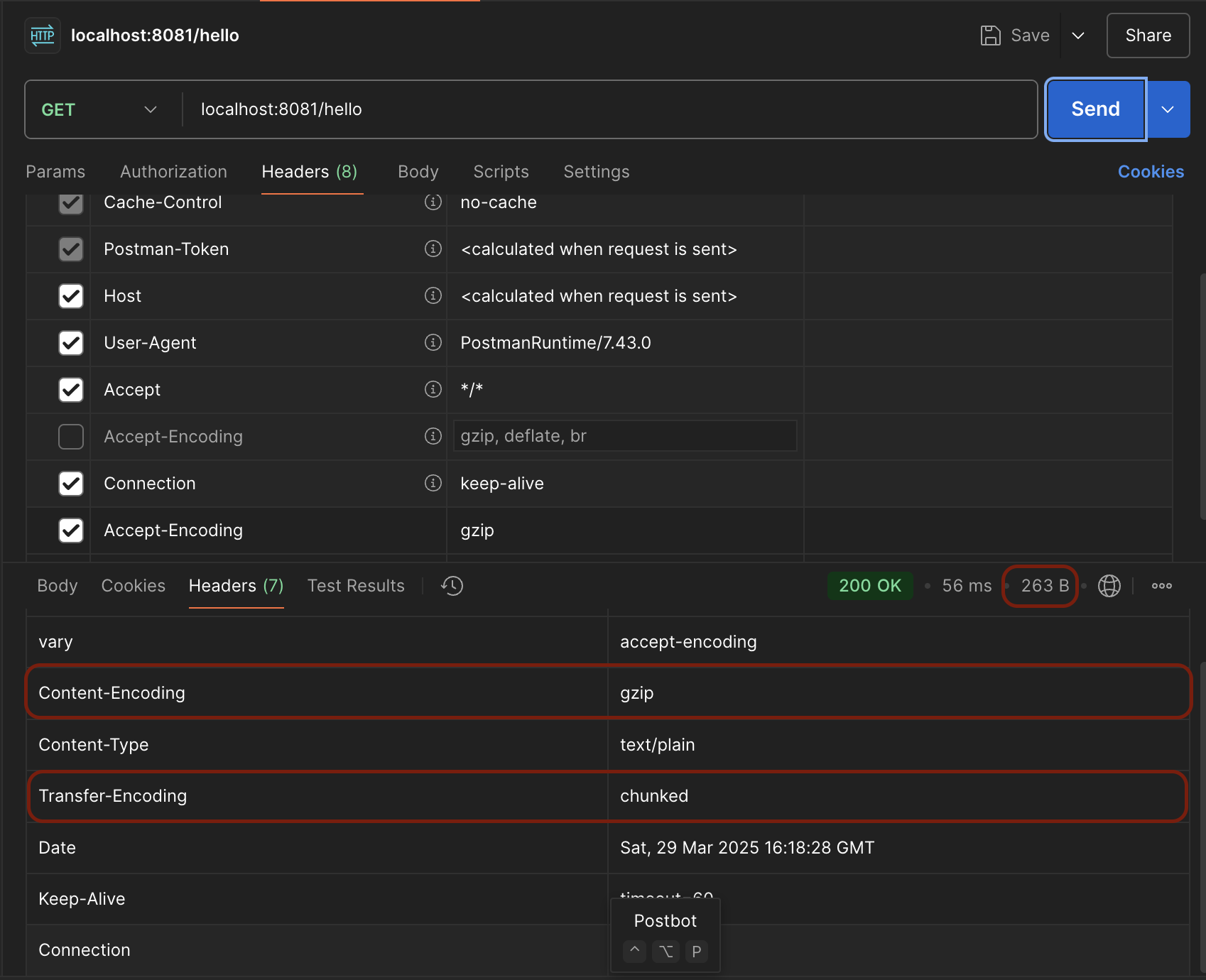 - 압축 후를 보면 Content-Encoding, Transfer-Encoding 헤더가 생겼다. - 또한, 압축 전보다 용량이 늘어난 것을 확인할 수 있다. - 그럼 나는 분명 압축을 했는데 왜 압축하기 전 보다 용량이 늘어났을까?
- 압축 후를 보면 Content-Encoding, Transfer-Encoding 헤더가 생겼다. - 또한, 압축 전보다 용량이 늘어난 것을 확인할 수 있다. - 그럼 나는 분명 압축을 했는데 왜 압축하기 전 보다 용량이 늘어났을까? - 원인은 바로
Transfer-Encoding:chunked떄문이다. Transfer-Encoding:chunked는 응답 길이를 모를 때 사용되며, 현재 스프링부트에서는 아래와 같은 상황일 때 기본 값으로 사용하는 것 같다.- 문서와 커뮤니티를 찾아봐도 정확한 해답이 없음…(추측)
- 응답 크기를 미리 알 수 없는 스트리밍 데이터(동영상 스트리밍, 실시간 로그 등).
- 매우 큰 동적 콘텐츠를 생성할 때 (전체를 메모리에 담아두기 부담스러울 때).
- 응답을 생성하면서 동시에 압축(Gzip 등)을 적용할 때 (최종 압축 크기를 미리 알기 어려움).
- 문서와 커뮤니티를 찾아봐도 정확한 해답이 없음…(추측)
Transfer-Encoding:chunked는 HTTP의 진화 포스팅에 작성해두었으니, 궁금하면 확인해보면 된다.- 결론적으로
Transfer-Encoding:chunked를 사용하여 오버헤드가 증가하여 응답 용량이 늘어난 것이다! - 즉, 작은 데이터는 압축하는 것보다 그냥 보내는 것이 낫다^_^
- 압축 하기 전
3. 네트워크 연결 계층에서의 압축(Hop-by-hop 압축)
Hop-by-hop 압축이란?
Hop-by-hop 압축은 이름 그대로 “hop”이라고 불리는 중간 노드들에서 발생하는 압축을 의미한다. 웹 서버와 클라이언트 사이의 경로 상의 특정 노드들(예: 프록시 서버, 중간 캐시 서버 등)에서 데이터를 압축하는 방식이다. 종단간 압축(end-to-end compression)과는 다르게, 서버와 클라이언트 간에 직접적으로 압축이 일어나지 않는다.
종단간 압축 vs Hop-by-hop 압축
- 종단간 압축 은 클라이언트와 서버가 서로 데이터를 주고받을 때, 데이터가 전송되는 서버와 클라이언트 간에 압축이 발생한다. 이 방식은 압축된 데이터가 종단(서버에서 클라이언트로, 또는 클라이언트에서 서버로) 전송되기 전에 압축된다.
- Hop-by-hop 압축 은 데이터가 서버에서 클라이언트로 전송되기 전, 그 경로 상에 위치한 중간 노드들에서 데이터를 압축한다. 이 방식은 각 중간 노드가 데이터를 압축하거나 압축을 해제할 수 있다는 점에서 차이가 있다.
어떻게 동작할까?
Hop-by-hop 압축은 HTTP 헤더를 통해 데이터를 처리한다.
- TE 헤더: 클라이언트가 중간 노드와의 연결에서 압축을 사용하겠다고 알리는 헤더, 이 헤더는 해당 압축 방식을 지원하는 서버와 노드들이 압축을 적용할 수 있게 한다.
- Transefer-Encoding: 데이터가 전송될 때, 압축 방식이나 다른 전송 방식이 무엇인지 알리기 위한 헤더, 이 헤더를 사용하면 데이터를 전송하는 중간 노드들이 데이터를 처리하는 방식을 결정한다.
실제 사례
Hop-by-hop 압축은 웹 서버 환경에서는 드물게 사용된다. 그럼에도 불구하고, 특정 네트워크 환경에서 성능을 극대화하려는 경우에는 여전히 사용된다. 특히 청크 전송(chunked transfer) 방식으로 데이터를 전송할 때 유용할 수 있다. 이 방식은 데이터 길이를 알지 못하는 상태에서 전송이 시작되므로, 중간 노드에서 압축을 적용하여 데이터 전송의 효율성을 높일 수 있다.