MySQL 구조

MySQL 구조
여태까지 MySQL을 사용하면서 단순히 “쿼리 날리면 결과 나오는 DB”로만 생각했다.
근데 Real MySQL이라는 책으로 MySQL을 공부해보니 흥미로운 점이 많았다.
MySQL의 내부를 들여다보면 구조가 정교하게 나뉘어져 있다.
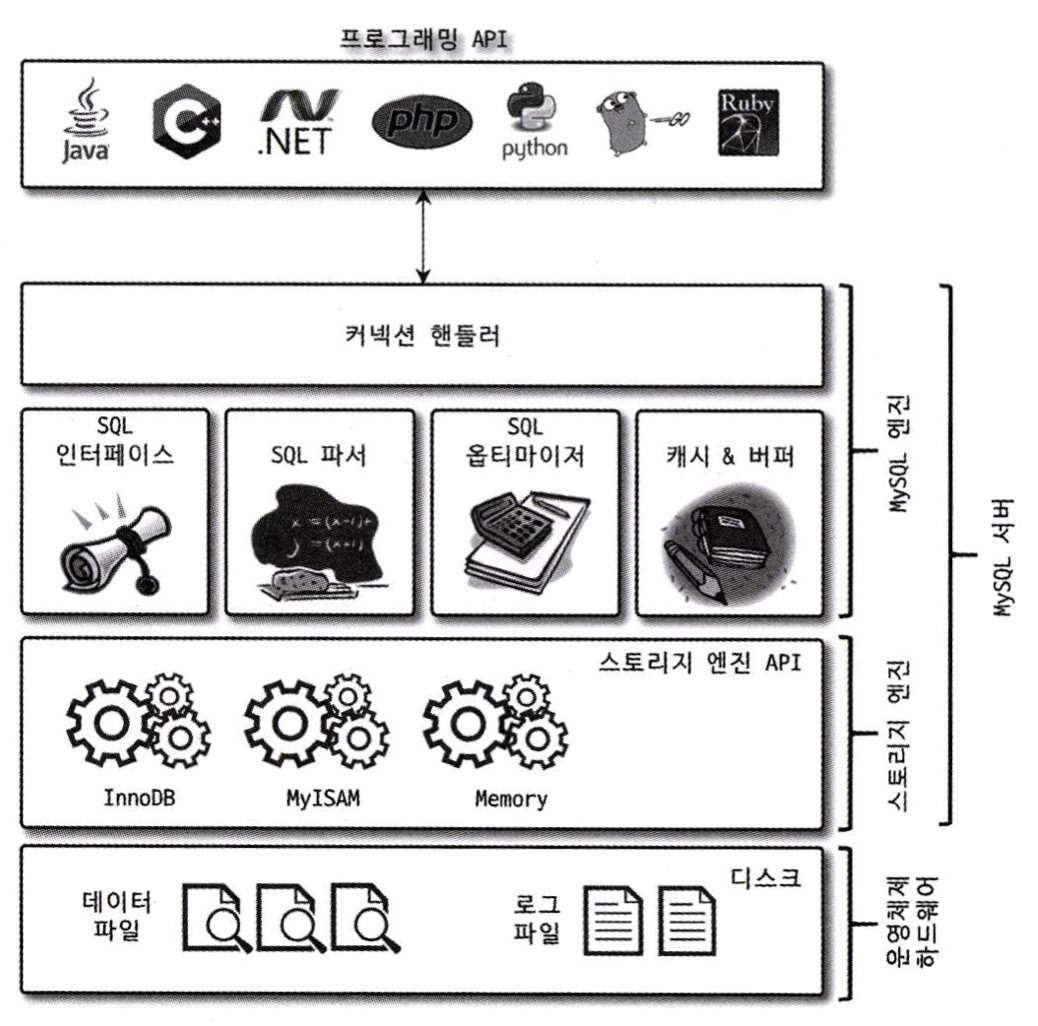
크게 보면 MySQL은 3덩어리로 나눌 수 있다.
- MySQL 엔진: 쿼리를 분석하고, 최적화하고, 어떻게 실행할지 판단하는 영역
- 스토리지 엔진: 실제 데이터를 디스크에 쓰고 읽는 영역
- OS & 하드웨어: 스토리지 엔진의 요청을 받아 실제 I/O를 처리하는 물리 계층
비유하자면 MySQL 엔진은 뇌(지휘소), 스토리지 엔진은 몸(실무진) 이다.
뇌가 “이 데이터 가져와”라고 명령하면, 몸이 실제로 움직여서 데이터를 가져온다.
핸들러(Handler) API: 둘 사이를 연결하는 인터페이스
MySQL 엔진은 스토리지 엔진에 직접 접근하지 않는다. 핸들러 API라는 인터페이스를 통해서만 소통한다.
1
2
3
4
5
6
7
MySQL 엔진 (쿼리 실행기)
│
▼
Handler API ← 표준화된 인터페이스
│
▼
스토리지 엔진 (InnoDB / MyISAM / Memory ...)
핸들러 API가 중간에서 표준화된 방식으로 통신을 처리해주기 때문에, MySQL 엔진 입장에서는 스토리지 엔진이 뭐든 상관없다.그냥 정해진 API만 호출하면 된다. 그래서 테이블 별로 스토리지 엔진을 다르게 주는 것도 가능하다.
왜 MySQL 엔진과 스토리지 엔진을 분리 해놨을까?
MySQL을 만든 개발자는 왜 굳이 MySQL과 스토리지 엔진을 분리해놨을까?
내 생각에는 SQL 처리 계층(MySQL 엔진)과 데이터 저장 계층(스토리지 엔진)을 분리함으로 써 다양한 스토리지 엔진을 플러그인 형태로 사용하기 위해서 인거같다.
이렇게 분리함으로써 각 서비스에 맞게 스토리지 엔진을 교체해서 사용할 수 있게 되기 때문이다.
“트랜잭션이 필요해? InnoDB 써.”
“빠른 읽기 위주 작업이야? MyISAM도 나쁘지 않아.”
“임시 데이터 처리야? Memory 엔진 써.”
이렇게 내가 운영하는 서비스의 요구사항에 따라 엔진을 갈아끼울 수 있게 된다.
MySQL 엔진
MySQL 엔진 안에도 역할이 나뉜다. 쿼리 하나가 들어오면 아래 순서로 처리된다.
1. 커넥션 핸들러
클라이언트가 MySQL에 접속하면 가장 먼저 만나는 곳이다.
- 클라이언트의 접속 요청을 받아 인증(계정/비밀번호)을 처리
- 인증이 통과되면 스레드를 하나 할당해서 이후 요청을 처리
MySQL은 클라이언트마다 스레드를 하나씩 붙여주는 스레드 기반 방식을 사용한다.
접속이 많아지면 스레드도 많아지니까, 이걸 최적화하기 위해 스레드 풀(Thread Pool) 을 쓰기도 한다.
2. SQL 파서 & 전처리기
인증이 끝나면 SQL 문장이 파서로 넘어온다.
파서(Parser)
- SQL 문장을 토큰으로 분리하고, 문법 오류가 있는지 확인
- 파싱이 완료되면 파스 트리(Parse Tree) 라는 트리 구조로 변환
1
SELECT name FROM users WHERE id = 1;
이 쿼리가 파싱되면 내부적으로 트리 형태로 분해된다.
“SELECT 절에 name이 있고, FROM 절에 users 테이블이 있고, WHERE 조건은 id = 1이다” 처럼.
전처리기(Preprocessor)
- 파스 트리를 받아서 테이블, 컬럼, 함수가 실제로 존재하는지 확인
- 해당 사용자가 그 테이블에 접근할 권한이 있는지도 여기서 체크
3. 옵티마이저
전처리까지 끝나면 옵티마이저가 등장한다.
옵티마이저는 “어떻게 실행하면 가장 효율적일까?” 를 판단하는 역할이다.
예를 들어 이런 쿼리가 있다고 해보자.
1
SELECT * FROM orders JOIN users ON orders.user_id = users.id WHERE users.age > 30;
옵티마이저는 여러 실행 방법을 검토한다.
users를 먼저 필터링하고orders와 조인할까?- 인덱스를 쓸 수 있을까? 어떤 인덱스가 더 효율적일까?
- 풀 테이블 스캔이 오히려 빠른 경우는?
이 판단 방식이 비용 기반 최적화 다.
옵티마이저는 각 실행 계획의 예상 비용(디스크 I/O, CPU 사용량 등)을 계산해서, 가장 비용이 낮은 방법을 선택한다.
실행 계획이 궁금하다면 쿼리 앞에 EXPLAIN을 붙이면 확인할 수 있다.
1
EXPLAIN SELECT * FROM orders JOIN users ON orders.user_id = users.id WHERE users.age > 30;
4. 쿼리 실행기 (Executor)
옵티마이저가 계획을 세웠다면, 실행기는 그 계획을 실제로 실행하는 역할이다.
실행기는 핸들러 API를 통해 스토리지 엔진에 요청을 날린다.
- “users 테이블에서 age > 30인 행 가져와”
- “orders 테이블에서 user_id가 일치하는 행 가져와”
이렇게 핸들러 API를 호출하면, 스토리지 엔진이 실제 데이터를 디스크(또는 메모리)에서 읽어서 반환한다.
스토리지 엔진
스토리지 엔진은 실제 데이터를 디스크에 저장하고, 읽어오는 물리적인 작업을 담당한다.
MySQL 엔진이 “이 데이터 줘”라고 요청하면, 스토리지 엔진이 파일 시스템에서 데이터를 꺼내온다.
대표적인 엔진은 세 가지다.
| 엔진 | 특징 |
|---|---|
| InnoDB | 트랜잭션, 행 단위 잠금, MVCC 지원. MySQL 8.0의 기본 엔진 |
| MyISAM | 트랜잭션 미지원, 테이블 단위 잠금. 읽기 위주 작업에 유리 |
| Memory | 데이터를 메모리에 저장. 빠르지만 서버 재시작 시 데이터 소실 |
InnoDB: 현대 MySQL의 표준
MySQL은 기본 스토리지 엔진으로 InnoDB를 지원한다.
그 이유는 ACID를 보장하기 때문이다.
- 트랜잭션:
BEGIN,COMMIT,ROLLBACK지원 - 행 단위 잠금(Row-level Lock): 다른 행은 잠그지 않아 동시성이 높음
- MVCC(Multi-Version Concurrency Control): 읽기 작업이 쓰기 작업을 방해하지 않음
InnoDB의 내부 구조(Buffer Pool, Redo/Undo Log)는 따로 깊게 다룰 예정이다.
그 아래엔: OS와 하드웨어
스토리지 엔진이 데이터를 읽고 쓸 때, 실제 I/O는 운영체제(OS)의 파일 시스템을 통해 일어난다.
그리고 그 파일 시스템 아래에 물리적인 디스크와 메모리가 있다.
1
2
3
4
5
6
7
8
9
10
MySQL 엔진
│
▼
스토리지 엔진
│
▼
OS 파일 시스템
│
▼
하드웨어 (디스크 / 메모리)
MySQL은 직접 디스크에 접근하지 않고 OS에 위임한다.
그래서 OS의 파일 I/O 성능이나 파일 시스템 종류(ext4, xfs 등)도 DB 성능에 영향을 준다.
이 부분은 InnoDB의 Buffer Pool을 다룰 때 더 자세히 나온다.
쿼리 한 줄이 실행되는 과정
지금까지 각 계층을 따로 봤으니, 이제 전체 흐름을 한 번에 정리해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
클라이언트
│
▼
커넥션 핸들러 → 인증, 스레드 할당
│
▼
SQL 파서 → 문법 분석, 파스 트리 생성
│
▼
전처리기 → 테이블/컬럼 존재 확인, 권한 체크
│
▼
옵티마이저 → 최적 실행 계획 수립 (CBO)
│
▼
쿼리 실행기 → 핸들러 API 호출
│
▼
스토리지 엔진 → 디스크/메모리에서 실제 데이터 처리
│
▼
OS 파일 시스템 → 실제 I/O 처리
│
▼
하드웨어 (디스크 / 메모리)
│
▼
결과 반환
각 계층이 자기 역할에만 집중하고, 인터페이스(핸들러 API)를 통해 소통하는 구조다.
MySQL 8.0에서 달라진 점
쿼리 캐시(Query Cache)의 삭제
MySQL 5.x 시절에는 쿼리 캐시 기능이 있었다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
커넥션 핸들러
│
▼
쿼리 캐시 ← 여기서 먼저 체크
│ (캐시 히트 시 바로 결과 반환 → 아래 단계 전혀 안 거침)
▼
SQL 파서
│
▼
전처리기
│
▼
옵티마이저
│
▼
쿼리 실행기
│
▼
스토리지 엔진
“같은 쿼리를 또 날리면 캐시된 결과를 그냥 돌려주자.”
하지만 여러가지 문제가 있었다.
- 테이블에 데이터가 단 한 건이라도 변경되면 해당 테이블과 관련된 모든 캐시가 무효화됨
- 쓰기가 잦은 서비스에서는 캐시 무효화 처리 비용이 오히려 성능을 떨어뜨림
- 캐시 키 관리와 메모리 단편화 문제도 있었음
결국 MySQL 8.0에서는 쿼리 캐시를 완전히 제거했다.
대신 애플리케이션 레벨에서 Redis 같은 외부 캐시를 쓰는 방식으로 대체하는 게 일반적이다.
결론
“판단은 MySQL 엔진이, 실행은 스토리지 엔진이!”
- MySQL 엔진은 쿼리를 분석하고, 최적화하고, 실행 계획을 세운다.
- 스토리지 엔진은 핸들러 API를 통해 요청을 받아 실제 데이터를 처리한다.
- 어떤 스토리지 엔진을 선택하느냐에 따라 성능과 ACID 보장 여부가 달라진다.
이해했는지 질문으로 확인하기
1. MySQL 엔진과 스토리지 엔진의 차이점은 무엇이고, 왜 이렇게 분리되어 있을까?
- MySQL 엔진은 SQL 파싱, 최적화 등 쿼리 전반을 관리하는 두뇌(기획/총괄) 역할을 하고, 스토리지 엔진은 디스크에서 데이터를 실제 저장/읽기하는 손발 역할을 한다. MySQL은 SQL 처리 계층과 데이터 저장 계층을 분리해서 다양한 스토리지 엔진을 플러그인 형태로 사용하기 위해 분리했다. 이렇게 분리해놓음으로써 서비스에 맞게 스토리지 엔진을 교체하여 사용할 수 있다.
2. InnoDB 스토리지 엔진을 사용하다가 MyISAM으로 바꾸면, SQL 문법도 바꿔야 할까?
- SQL 파싱 부분은 MySQL 엔진에서 처리하기 때문에 스토리지 엔진을 바꾼다고 문법 자체를 바꿀 필요는 없다.
3. 서로 다른 스토리지 엔진을 사용하는 두 테이블을 JOIN 할 수 있을까?
- 스토리지 엔진은 데이터만 전달하고 JOIN 처리는 쿼리 실행기에서 하기 때문에 할 수 있다.
4. 쿼리 실행기(Executor)와 핸들러 API는 어떤 관계일까?
- 쿼리 실행기는 핸들러 API를 통해 스토리지 엔진과 소통하며 데이터의 정보를 가지고 올수 있다.
참고 자료
MySQL 공식문서
Real MySQL 8.0
[10분 테코톡] 릭의 MySQL 아키텍처
[10분 테코톡] 아코의 MySQL 아키텍처